VLA (review)
写在前面
我们能否让这些模型在全新的环境里,稳定地完成我们以前从未见过机器人做过的任务,那些非常灵巧、非常长周期、非常复杂的任务?
🌟:表示AI Lab出品
Summary
Table 1 可能并不完整的简陋VLA Collection
| Name | model | data | speed | benchmark | task | hardware | action |
|---|---|---|---|---|---|---|---|
| $\pi_{0}$ | PaliGemma | Cross-em | 73ms/H=16 | ATP/FR/SR | HL+LL | 7 manipulators | flow |
| $\pi_{0.5}$ | PaliGemma | multi-modal | 50Hz | ATP/FR/SR | HL+LL | wheeled 6D | flow |
| Gr00t | Eagle-2+DiTFM | Real&syn&video | 63.9ms/H=16 | 3sim4real | sim+LL | GR-1/cross | flow |
| GR-3 | Qwen2.5VL+DiTFM | VL+robot+human | - | ATP/SR | HL+LL | PICO 4+7-DoF | flow |
| RT-1 | EfficientNet | real world | 3Hz/100ms- | SR | real | kuka/everyday | token |
| RT-2 | PaLI-X/PaLM-E | real+VL-QA | 1-5Hz | SR | real | 7DoF | token |
| OpenVLA | Llama 2 7B | Open X | 6Hz | SR | real&sim&ood | Franka | token |
| GraspVLA | InternLM | Syn(SynGrasp-1B) | 5Hz on 3090 | LIBERO | real+sim | Franka | flow |
| ChatVLA | Qwen2-VL+DiVLA | mixed | no mentioning | MM-series,sr | real | Franka | diffusion |
| Gr00t 1.5 |
这些天把paper看下来,有一种VLA的发展还困在dataset和evaluation质量(当然相应地还伴随着对dataset采用何种训练范式)中的印象。
仅仅一表,寥寥数言难以概括,所以准备再单独去总结一下data、benchmark/task这两个最关键的部分的情况。后面我可能也focus在数据和benchmark问题上去开展工作了。
而且,各个××VLA同质化得吓人,浮躁之气扑面而来,说是$\pi_0$魔改也不为过
菜的好处就来了,可以容易地忘记tech,胡乱想一想别的技术路线(狗头),重要的是完成任务,不是VLA。
所以我们希望机器人完成的到底是什么样的任务呢?
我斗胆瞎起个名字,Autonomous Global Task Decomposition and Execution。最后希望能看到nav和manip的融合,这才是最贴近落地场景的任务,不过现在两方面发展的都一般,还没到融合的时机,盲目去做恐怕只会增加问题的复杂度。
RT-1
RT-1: Robotics Transformer For Real-World Control at Scale
- paper link: https://arxiv.org/pdf/2212.06817
- time: 2022/12(老大哥!)
- core idea:
- ✅ modern machine learning models -> computer vision, natural language processing, speech recognition
- ❌ modern machine learning models -> robotics
- ❓ the difficulty of collecting real-world robotic data
- 🔨 open-ended task-agnostic training & high-capacity architectures for all of the diverse, robotic data
- 🏅 Robotics Transformer exhibits promising scalable model properties: Ability = F(data size, model size, data diversity)
- reading note:
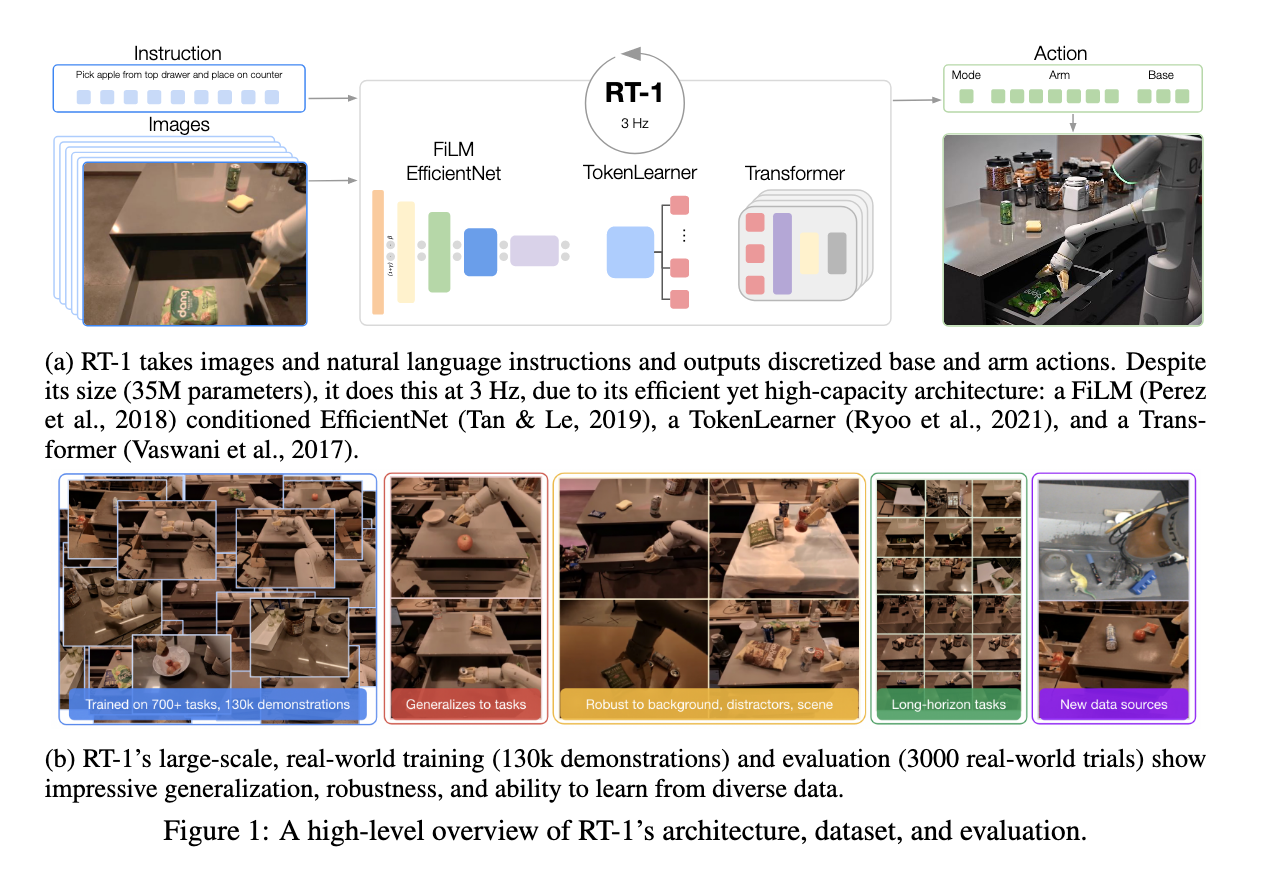
- 某种程度上说,应该是尝试大模型到robotics应用的第一篇paper。motivation来自于深度学习这一轮的兴盛。基于深度学习Transformer架构的大模型对视觉、自然语言处理等下游任务有很好的支持和效果革新,自然,机器人的action生成也许也可以作为一种下游任务试一试。这一直接带出了具身智能领域的创新,在当时的名字挺直白:Robotics Transformer。
- 而这个下游任务做得晚的原因,就是real world机器人数据收集的困难性。这个问题其实到现在也很难说解决了多少。在这篇开坑性质的文章中,解决这个问题的尝试用的是一个有130k demonstrations的real-world training数据集,evaluation用的则是3000个real-world trials。
- 都说real world数据收集难,为什么他们就可以做?从appendix里面可以看到答案,是一点点收集的,是典型的工业界做高质量真实数据收集的优势。只不过,很显然,这个数据集计数用的是k,而视觉、language相关的用的是M。即使数据只有V\L的零头,仍然可以取得比较突破性的成果,希望能早点看到robot data scaling开始的那一天。
RT-2
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
- paper link: https://arxiv.org/pdf/2307.15818
- time: 2023/7
- core idea:
- ❓ how VLM & Internet-scale data -> end-to-end robotic control
- 🗒️ co-fine-tune SOTA VLM on both robotic trajectory data and Internet-scale vision-language tasks
- 🗒️ actions treated in the same way as natural language tokens
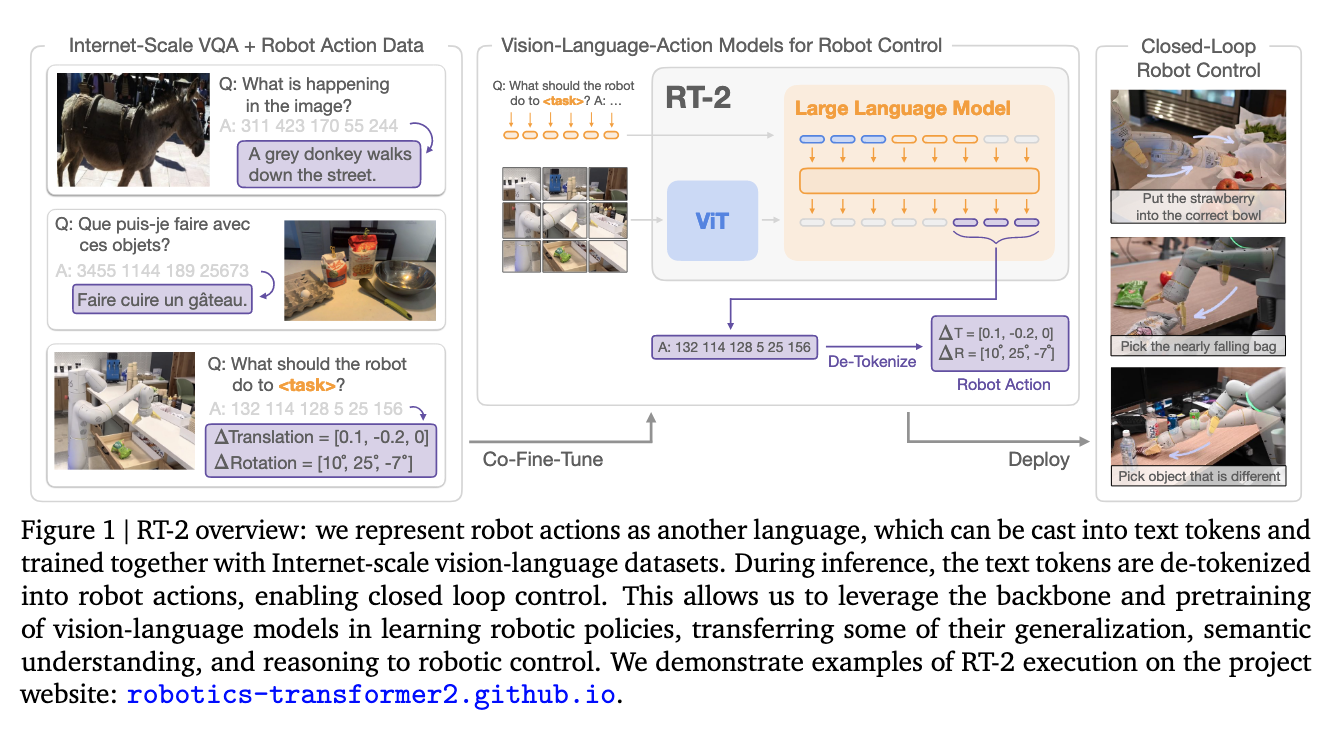
- We refer to such category of models as vision-language-action models (VLA) and instantiate an example of such a model, which we call RT-2. Our extensive evaluation (6k evaluation trials) shows that our approach leads to performant robotic policies and enables RT-2 to obtain a range of emergent capabilities from Internet-scale training. This includes significantly improved generalization to novel objects, the ability to interpret commands not present in the robot training data (such as placing an object onto a particular number or icon), and the ability to perform rudimentary reasoning in response to user commands (such as picking up the smallest or largest object, or the one closest to another object). We further show that incorporating chain of thought reasoning allows RT-2 to perform multi-stage semantic reasoning, for example figuring out which object to pick up for use as an improvised hammer (a rock), or which type of drink is best suited for someone who is tired (an energy drink).we represent robot actions as another language, which can be cast into text tokens and trained together with Internet-scale vision-language datasets.
- reading note:
OpenVLA
是万恶之源!
paper link: https://arxiv.org/pdf/2406.09246
time: 2024/06
core idea:
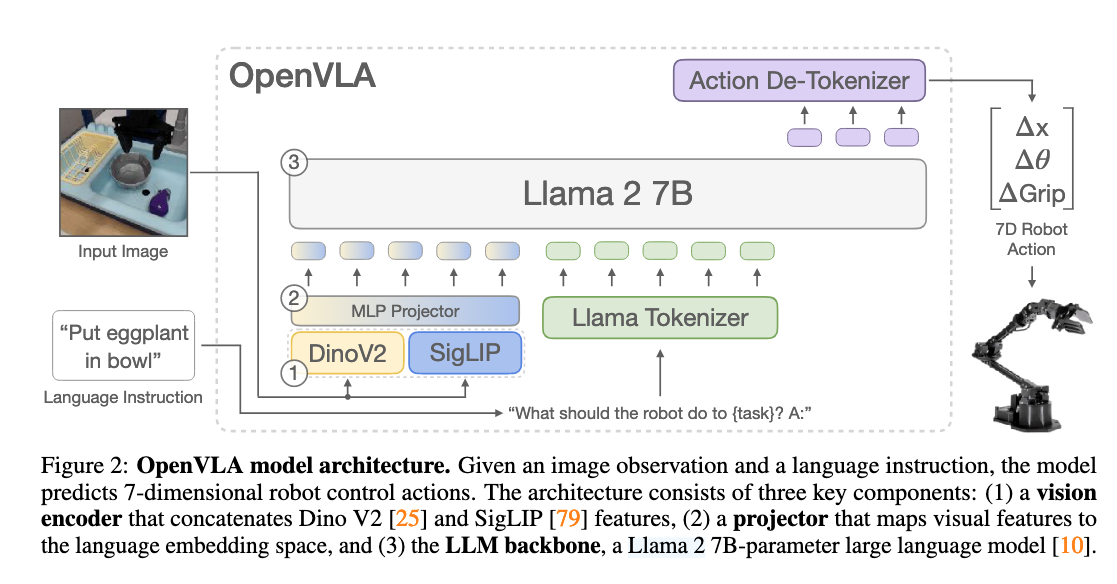
- A 7B-parameteropen-source VLA trained on 970k robot episodes from the Open X-Embodiment dataset, v-feature from DINOv2 and SigLIP and l-feature from Llama 2
- Efficiently fine-tuning VLAs for new tasks as a key component for adoption
- Outperforming RT-2 (55B) by 16.5%, outperform diffusion policy by 20.4% (in absolute task success rate across 29 tasks and multiple robot embodiments with 7x fewer parameters)
reading note:
- VLA最早溯源到RT-2,两年过去了(在AI的尺度上感觉过了几十年…)还是在解决’generalize beyond their training data’的问题。解决adaptation的问题关键还是在于微调适应特定下游任务的效率和效果,所以openVLA的点主要是做work了首个VLA的fine-tune方法
- Visual encoder加了DINOv2效果会更好,那换成理解其他视觉信息的模型OK吗(搭积木思路有了)
- Action的mapping方式是discrete tokens,然后把Llama最不常用的256个token给overwrite了(会不会导致一些prior-bias?)
- omg 21500 A100 hours…想知道参数量最小的能够保持同一水平的VLA有多大,这个任务可不可以多个小模型去做而不是要训练这么久
- 纸上得来终觉浅,滚去看代码了,明天准备跑一下
推荐指数:🌟🌟🌟🌟
$pi_{0}$
是另一个万恶之源!

paper link: https://www.physicalintelligence.company/download/pi0.pdf
time: 2024/10
core idea:
- (被后来者反复用的)Model: flow matching architecture built on top of a pre-trained vision-language model (VLM) to inherit Internet-scale semantic knowledge.
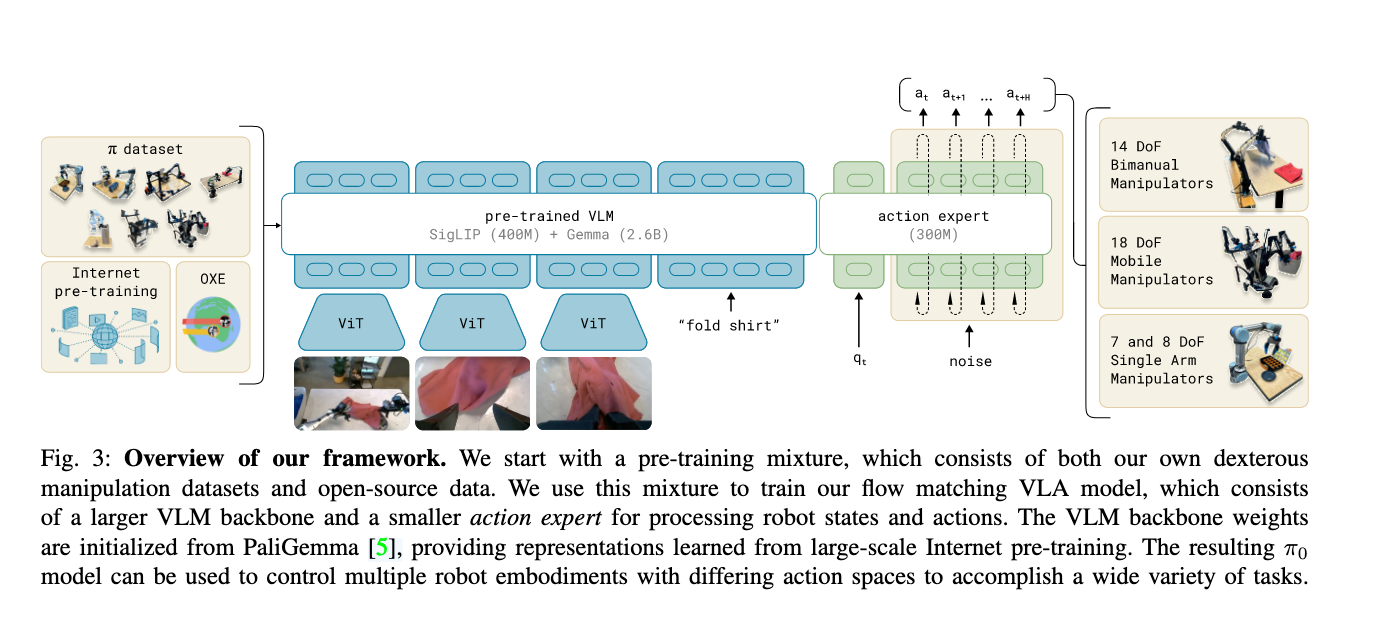
- VLM -> Internet-scale experience
- action chunking with flow matching -> crossembodiment training
- Dataset: post-training dataset for difficult/unseen tasks
- Time: control robots at frequencies of up to 50 Hz for dexterous tasks
- Evaluation: 1 perform tasks via direct prompting, 2 follow language instructions from people and from a high-level VLM policy, 3 acquire new skills via fine-tuning.
- (被后来者反复用的)Model: flow matching architecture built on top of a pre-trained vision-language model (VLM) to inherit Internet-scale semantic knowledge.
reading note:
- action expert可以支持不同自由度的arm
- action chunk
推荐指数:🌟🌟🌟🌟
$pi_{0.5}$
- paper link:
- core idea:
- reading note:
- 我想思考一件事情,那就是$pi_{0.5}$在泛化到它没有见过的场景中的时候,它用了多少视觉信息和房间map的信息?video中position的跨度让人怀疑它是否已经把navigation包含了进去(写下这段话的同时看到了$Nav^3$, 很想去做让navi与manip融合的新任务,进一步high level直到能够适配现实需求)。(二编:在单个任务没做好的时候不要试图给自己增加复杂度。)
- baseline:见过training location; ours:没见过 training location。但是二者表现相近,可以作为证明。
Gr00t
An Open Foundation Model for Generalist Humanoid Robots
仔细看了一下🫨原来是humaniod vla吗怪不得某些人天天跟我提这个…不过也没什么大区别,下半身没动,单双臂和人形不过是一层MLP的action head的区别罢了
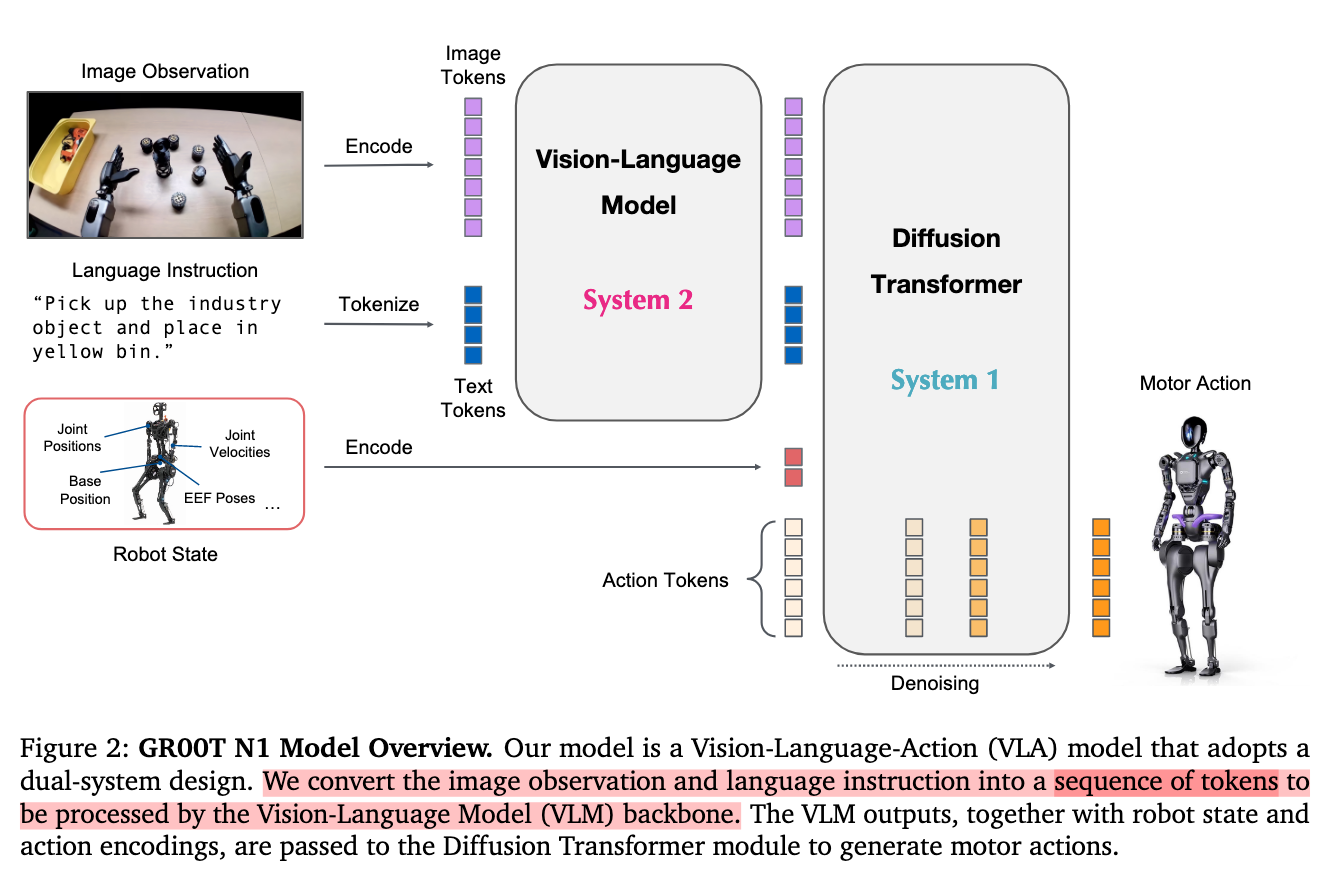
paper link: https://arxiv.org/pdf/2503.14734
time: 2025/03
core idea:
- real & sync & video and web 数据构建“a consistent dataset where the input consists of the robot state, visual observations, and language instruction, and the output is the corresponding motor action”, for end-2-end pretrain.
- Post-training with Neural Trajectories(leveraging video generation model)
- GR00T N1: Action encoder & time encode & vl tokend在DiT中cross attention融合,然后过action decoder(iterately generate actions)
reading note:
- 不愧是Nvidia,读之扑面而来的细节感。才到Section 2已经把model参数和GPU time给端上来了, formulation也无比清晰。
- 支持部署在单臂双臂和humanoid(不含下半身policy)上
- 具体model选择堪称奠基性工作,后知后觉地发现很多工作的model都是照搬开源的Gr00t()
- 没太多可说的,逐字阅读就完了。writing令人如沐春风,dataset做得太好了。
推荐指数:🌟🌟🌟🌟🌟
GR-3 by bytedance
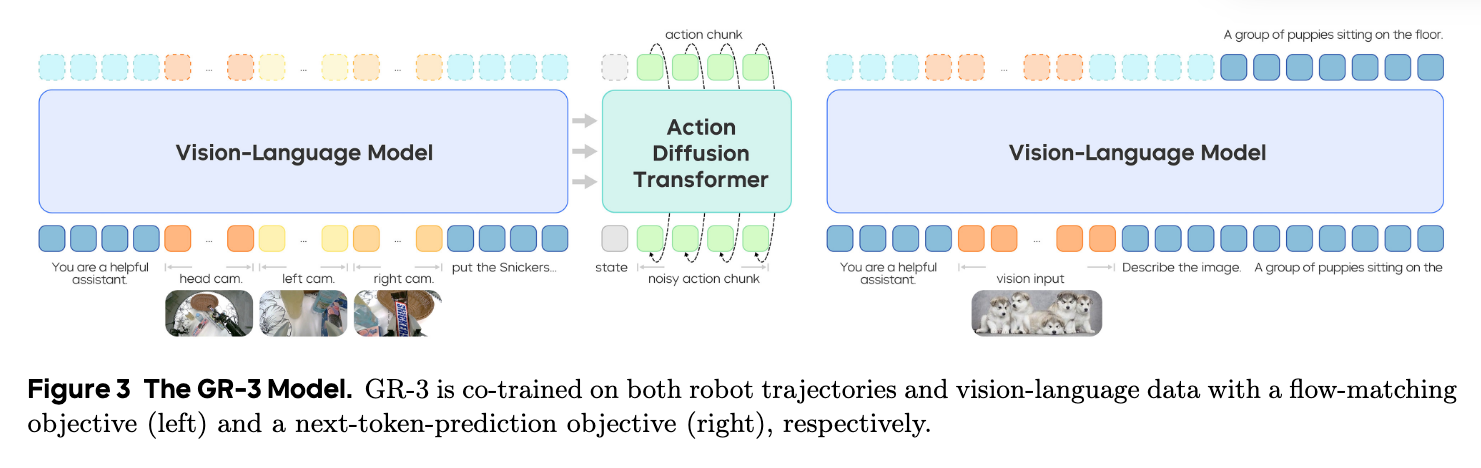
paper link: https://arxiv.org/pdf/2503.14734
time: 2025/07
core idea:
- Model: 是小而美的Qwen2.5-VL-3B-Instruct!Flow matching是一脉相承的DiT,Flow matching timestep is injected via the adaptive layer norm (AdaLN)(学$\pi_{0.5}$?)
- Data:
- Training Recipe:
- Inference: the action DiT contains half the number of layers compared to the VLM backbone and utilizes only the KV cache from the latter half of the VLM layers.
reading note:
- 虽然都是套路相似的VLA,但我永远喜欢字节蓝(误🔵)排版和画图真的好好看呀😭
- Human trajectories 450/h(VR), teleoperated trajectory collection 250/h,不过他们用的VR眼镜是PICO 4 Ultra Enterprise
推荐指数:🌟🌟🌟🌟
GraspVLA
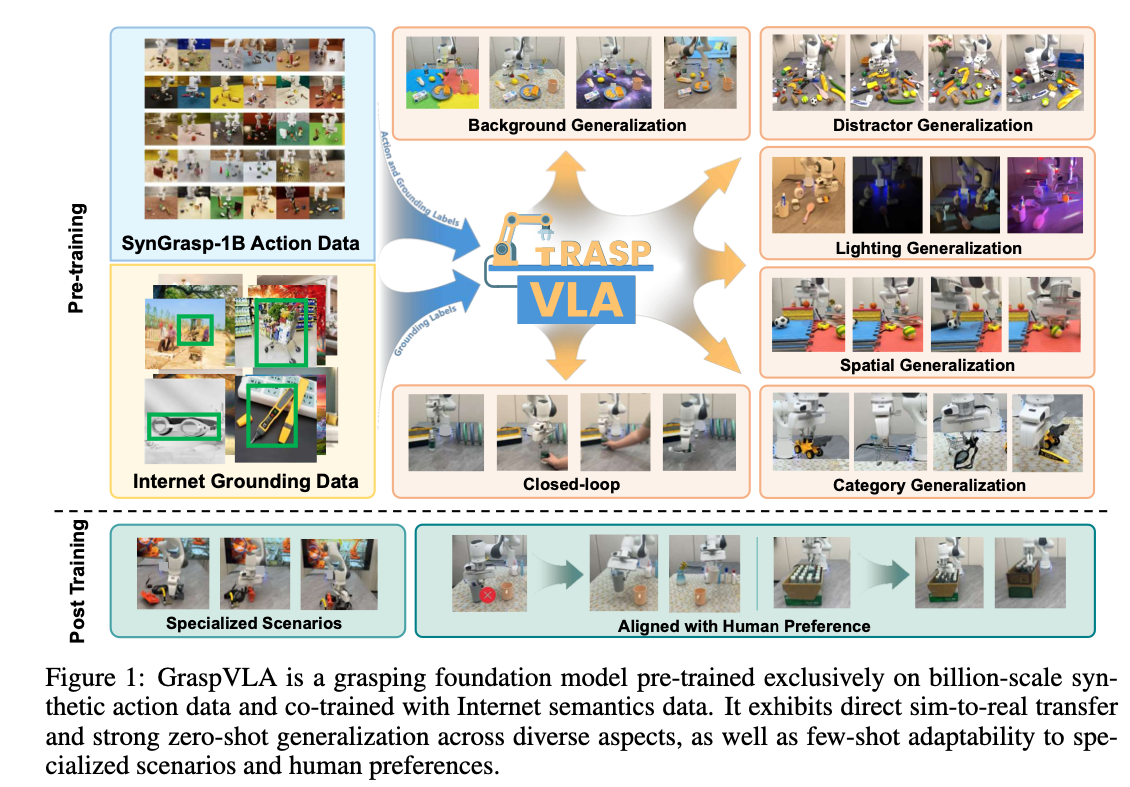
- paper link: https://arxiv.org/pdf/2505.03233
- time: 2025/05
- core idea:
- 4
- reading note:
- 对cv人来说(虽然半路出家的我cv思维并不太根深蒂固)最大的亮眼之处就是超大的合成数据集SynGrasp-1B了,简直是合成党狂喜好不好!非常impressvie,SynGrasp-1B using 160 NVIDIA 4090 GPUs for 10 days,160✖️240的4090 hours啊。
ChatVLA
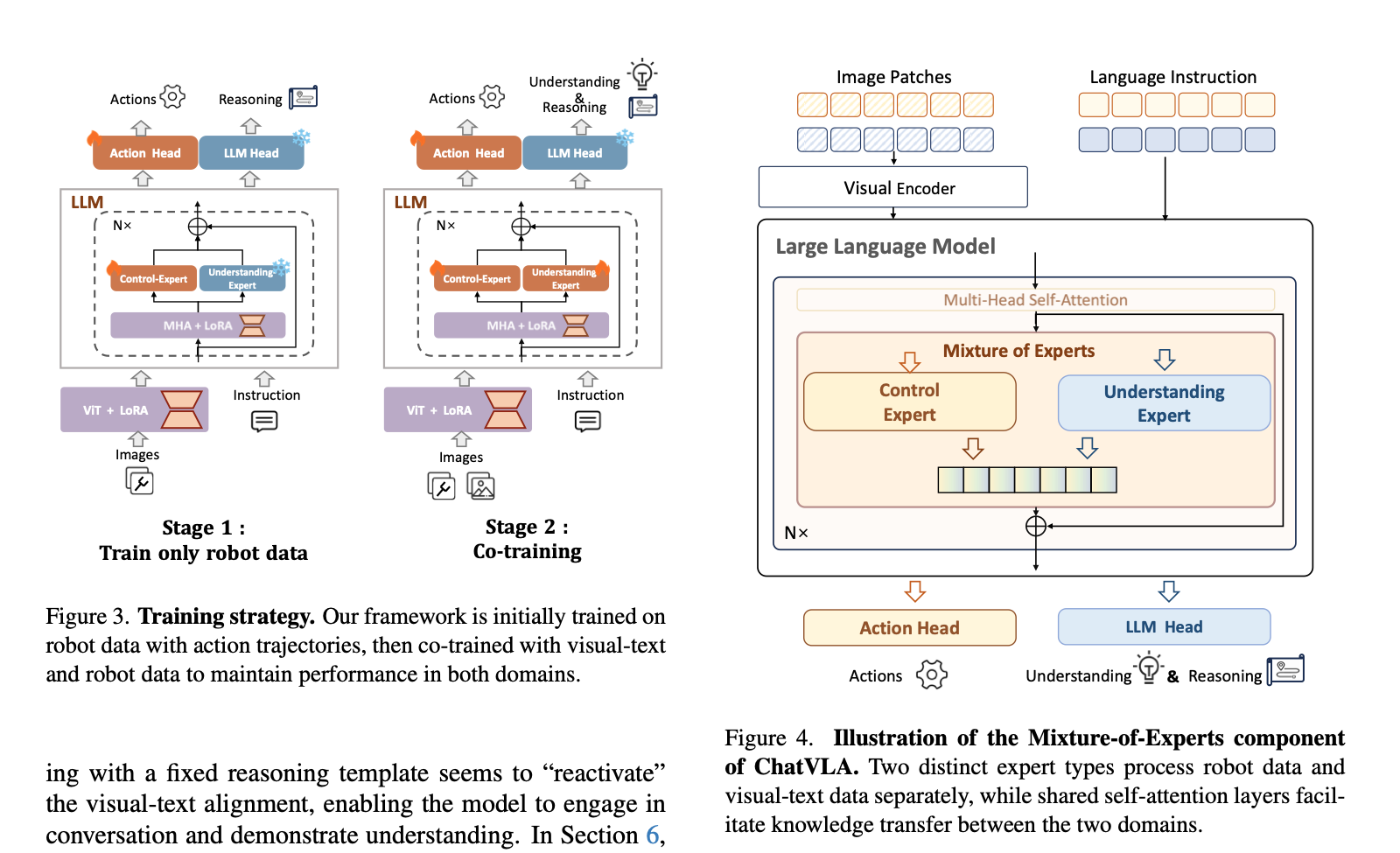
- paper link: https://arxiv.org/pdf/2502.14420
- time: 2025/02
- core idea:
- VLA challenges: spurious forgetting & task interference
- ChatVLA solution: a MoE framework featuring Phased Alignment Training
- reading note:
- 多模态理解和操作能力的训练打架问题是不是各种五花八门的VLA都在解决的老生常谈?所以说VLA的本质是VLM。感觉套路好像,提出一种新的训练recipe,然后刷刷MM understanding的榜,刷刷manip task success rate,取得一个双冠,然后成一篇paper(不过这篇是不是第一个加入VL understanding data做的诶)。
- 本文中的新training recipe叫做Phased Alignment Training,核心思想是curriculum learning,文章说的是什么“先掌握具身控制”,然后“逐步地整合多模态数据”,“重新激活对齐”,反正看字面意思是看不懂的。后面具体操作是“Following RT-2, we used a 3:1 ratio of robot data to visual-text data in this experiment”,以及用纯robot control data和CoT reasoning两种训练作为baseline对比。
- 我发现这些paper怎么就是不提训练用的task和loss呢(是因为跟VLM套路类似,或者因为跟dataset绑定,所以不用特意提?也许吧,我还是去找个开源的看看代码)
🌟GenManip
- paper link: https://arxiv.org/pdf/2506.10966

time: 2025/06
core idea: policy generalization
- platform内容1: LLM自动生成ToSG并进一步生成task的pipeline(含10k 3d assets)
- platform内容2: benchmark for generalization of modular manipulation systems & end-to-end policies trained through scalable data collection, the former with better generalization.
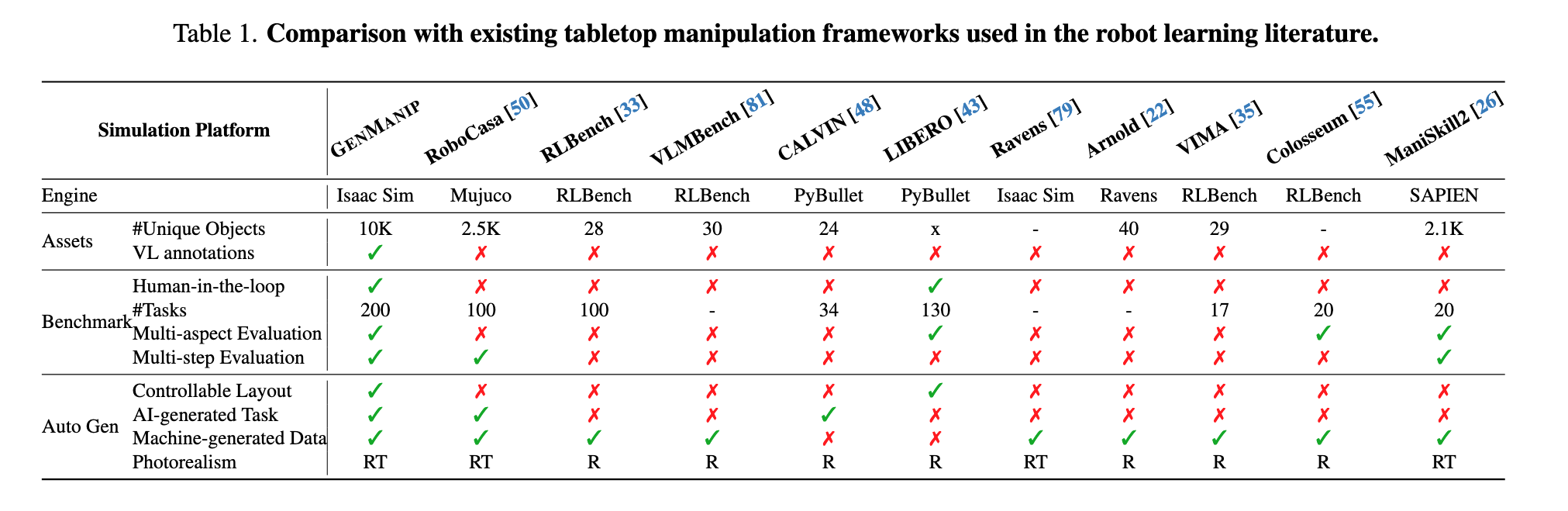
reading note:
- 3
- 文中用GPT-4V生成的Task-oriented scene graph(ToSG)可真像3DISS算layout可行解用的graph
推荐指数:
🌟InstructVLA
- paper link: https://arxiv.org/pdf/2506.10966
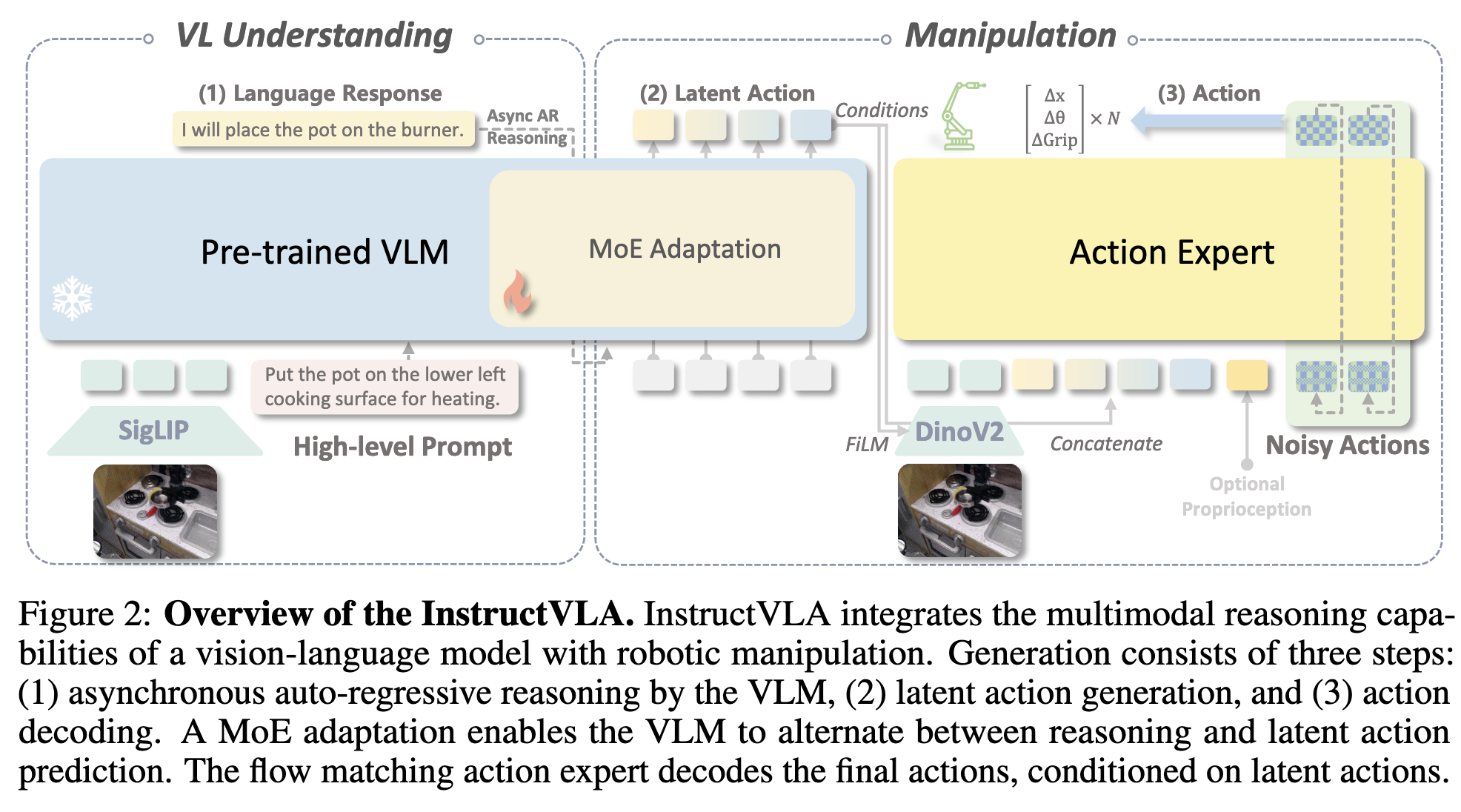
time: 2025/07
core idea:
- Model: 原文“treating language-steered action generation as an integral component of instruction following”,感觉可以说是“垫”了一下,从直接vlm生成latent action,到vlm只负责生成action描述,再用MoE从action描述生成latent action,其中MoE可以fine tune。训练一个work、make sense的特定任务能力。有点像layoutVLM的思路。
- VLA-IT dataset, consisting of 650K human-robot interactions annotated with diverse instructions, scene captions, and question-answer pairs grounded in high-quality manipulation tasks
- SimplerEnv-Instruct benchmark
reading note:
- 非常impressive的行文逻辑闭环。vision+language+manip混训忽略了complex embodied reasoning, embodied reasoning(CoT加持)+manip混训一般会用action和reasoning的structure去组织训练,限制mm推理能力。围绕“integrate multimodal reasoning with precise action generation”展开的
- 不想损失mm推理能力,保留一部分VLM❄️不训练,VLM的作用只是提供language description for action,随后MoE把它变成latent action这一步要训练,训练所用的就是VLA-IT dataset。这个VLA-IT dataset本意在于提高action的language分解能力,但似乎因为data过于丰富把mm reasoning的榜也刷高了一些(MMMU之类的)
- large heterogeneous datasets的具体做法?This framework is jointly trained on multimodal datasets
- formulation比较一般,都在appendix里面,而且看着跟GR00T可谓是似曾相识(?)
- 和我想的那种action分解不太一样,依然是没有考虑environment的简单action推理分解
- ❓为什么要用Eagle2-2B作为VLM的backbone?这个半年前的Nvidia backbone有什么特别的么
- ❓虽然writing和画图水平都令人心旷神怡,但为什么没video demo?主要是强调benchmark和dataset吗
推荐指数:🌟🌟🌟
Seer
paper link:
time: 2025/07
core idea:
reading note:
RAGnet
- paper link: https://arxiv.org/abs/2507.23734