3D Scene Synthesis
写在前面
科研motivation发源于concern,我的concern就是如何更省力地拥有一个整洁舒适的家,所以我希望自己以后的工作能围绕着家居机器人展开。 再加上我的科研是从3D scene开始的,对3D indoor scene synthesis总是有一种亲切感。
总体来说:
- 23年底24年初之前diffusion占主流,但是diffusion是刻画dataset的distribution的,3D scene dataset很难做得像2D那么大,标注成本也大得多
- 24年之后转向更加自由、更加有合成丰富dataset潜力的open vocabulary任务,采用的范式可以总结为VLM & LLM prompt+规定好位置锚定关系后求出一个可行的bbox位置相关的解
- 同步出现的工作开始搞Agent framework(尝试各种VLM/LLM在充当Designer agent的时候对话和合作的形式)和新task(例如单个object placement, 可控性更强)
- 虽然这些工作都是3DISS,但是task有一些细微差别,例如prompt细致程度不同,有的paper text给的非常详细,看模型text2scene的能力,有的paper prompt简短,交给模型自行发挥。
但是个人觉得重点不在sim下游的nav和manip training的话,其实变着花样搭建pipeline容易本末倒置(其实把prompt写好一些,4o就能达到很好的效果,不需要搞那么多framework),为了生成而生成怎么也比不上外包给数据标注公司效果好。所以相关paper还是最喜欢有不错的下游应用的ACDC。
插一句嘴,这个表不错:

ACDC
- paper link: https://arxiv.org/abs/2410.07408
Tag:
core idea:
- Digital Cousins: 简化版digital twin,does not explicitly model a real-world counterpart but still exhibits similar geometric and semantic affordances
- 具体区别:放掉了部分场景细节,把场景用更high-level的维度抽象出来,例如空间关系和semantic affordances
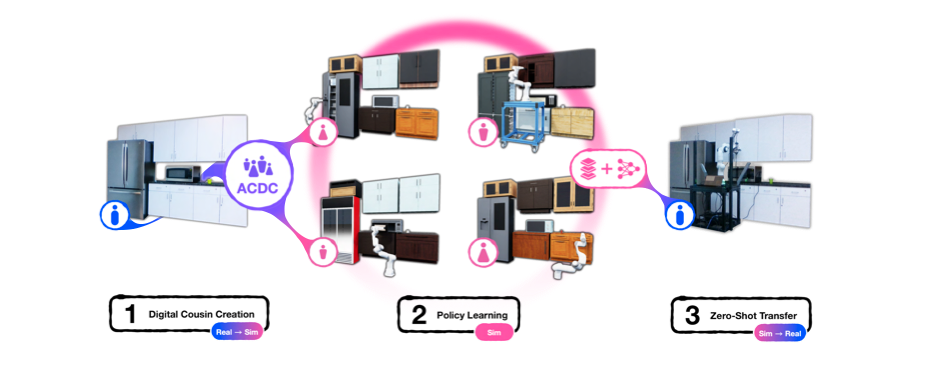
- A novel method for Digital Cousins’ automated creation,从2D RGB image到
- A fully automated real-to-sim-to-real pipeline for generating fully interactive scenes and training robot policies that can be deployed zero-shot in the original scene.
reading note:
- 喜欢这篇文章的一大原因是3D室内场景/物体生成经常是为了蹭具身而蹭,真正拿自己生成的东西做下游应用(在我有限的科研见解中应该主要是manip)的很少。核心的idea是为了降低成本提高效率,尝试把digital twin这样的重建复刻变成了digital cousin,“亲缘”更远,但抓住场景构成的本质。
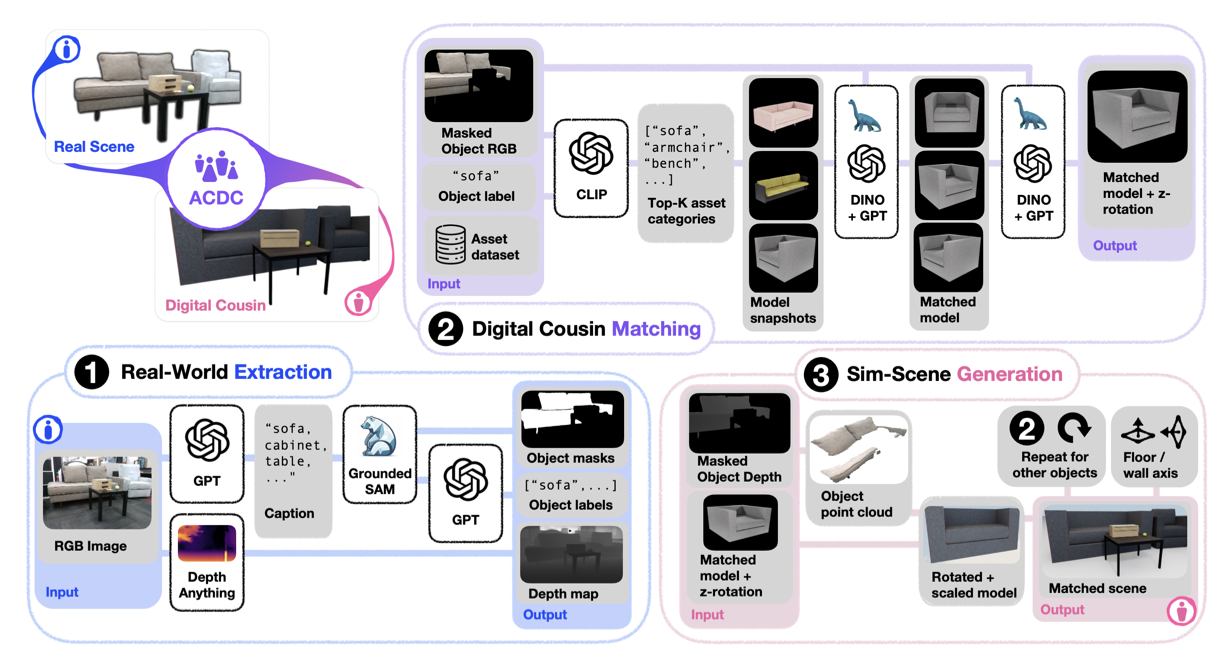
- 提出DC并构建了DC相关的生态ACDC(Automated Creation)。第一步是real2feature,给real world image,用GPT做一下caption,得到object masks,labels和depth map。第二步是feature2sim,用DINOv2这样一个visual encoder提取images的geometric feature(因为point cloud在一张scene image中occulsion严重),用来衡量digital assets的相似度,综合类别和geo feature排序,得到最match的model和z轴+rotation信息。第三步是从assets到scene,主要是按照point cloud先大致确定bbox,然后根据投影重叠规则确定物体间叠放关系,作位置微调等。
- 然后就是imitation policy learning啦,事实证明digital cousin的“亲缘”也已经足够进行zero-shot transfer,Open, Close, Pick, and Place,demonstration收集,启动!
- 这种用Q1 Q2 Q3来组织experiment writing的方式挺清晰的,也是一种提前“答审稿人问”了吧,网页里展示的生成过程对时间的重视比我们的项目更清晰,确实值得学习(我们没有提单个case的生成时间也被审稿人喷了),有一点就是可能sim2real的zero shot效果的场景有点少(我鸡蛋里挑骨头),没有完备地跑一下各个类别。
推荐指数:🌟🌟🌟🌟
二编:部署踩坑。这个里面用的submodule实在是太多了,诸如dinov2, SAM-2,groundingDINO,Depth-Anything-V2,OminiGibson一大堆。深刻体会了一把什么叫拼积木工作,环境非常不好配(为啥不直接给个once-for-all的environment.yml)。为了体会整个ACDC pipeline,硬着头皮配了两天的环境。然后下载BEHAVIOR资产的时候服务器用不了urllib,代理问题报错[104]。看了一下集群的飞书群,感觉没什么好办法,只好扒代码把checkpoint手动下载下来,传入目标destination。
我的个妈,这么多submodule,我的cfps快被占满了,本来就是想速通一下玩玩,结果搞了两三天…舍不得放弃,继续往下搞咯。
Physcene
paper link: https://physcene.github.io

core idea:
- 新任务,interactive 3D scenes synthesis,着重强调physical plausibility and interactivity
- 但是23年的工作,那会还比较流行train diffusion做layout synthesis,要加噪的是一个$o_i$的label,size, r, t和shape feature。
- diffusion方法对object的表征注定了model的生成范围比较依赖数据集,所以要生成interactivity的scene,首先得有articulated object的dataset(GAPartNet)
- 从上一步采样的时候把与physical plausibility有关的函数$\phi_{roll}$等考虑进$\mu$里(这类细节在24年之后逐渐被直接提醒MLLM注意的prompt取代了)
- 对于铰链物体(做科研之前这个名词在高中物理卷子上出现得最多hh),把打开之后的最大bbox作为范围进行$\phi_{roll}$等的计算
reading note:
- Formulation很漂亮(我终于能看懂formulation了可喜可贺)
- diffusion时代用dataset评估,有GT,还能算FID SCA CKL,但是对于完全开放的生成任务就没什么好指标了 sigh, 经常出现4o评4o
- diffusion在23年还是挺常见的(ATISS, diffuscene, LEGO-net),亮点就是guidance function(physical plausibility的融入方式)和articulated object的处理方法
推荐指数:🌟🌟🌟
Fireplace
- paper link:https://arxiv.org/pdf/2503.04919
time: 2025/03
core idea:
- place new 3D objects into complex, preexisting 3D scenes
- Input: a 3D scene, a 3D object, and a language prompt. Output: Object placements
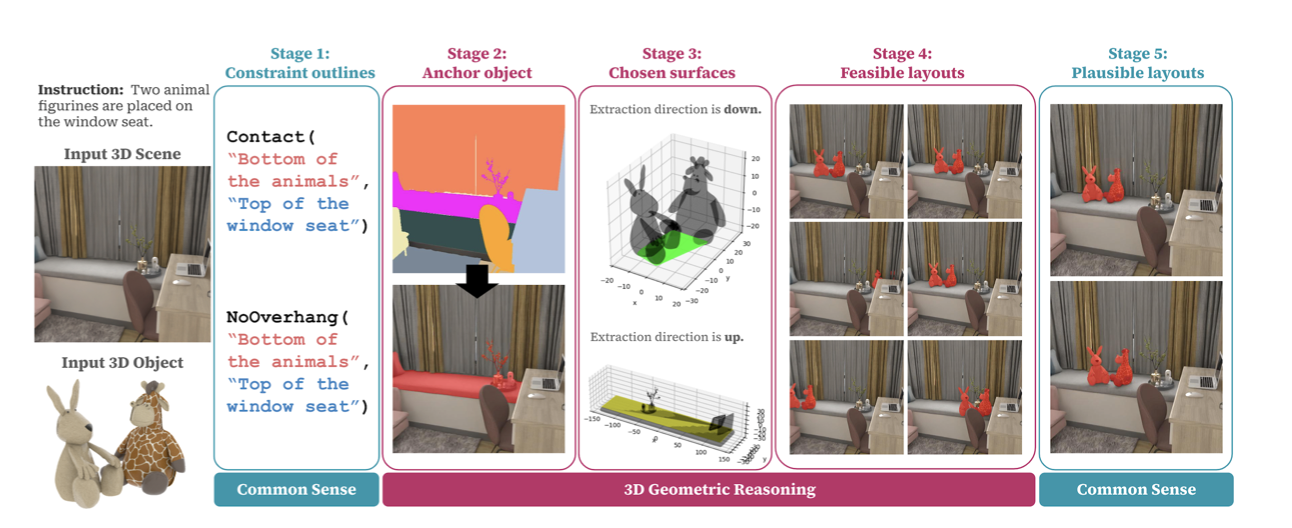
- Method概述:pipeline类,不需要train model。整个pipeline堪称对MLLM的疯狂奴役(bushi)。根据定义好的要求和input,先找到Anchor object,再找到要处理的surface,生成需要满足的constrain function,placement的constrain主要表现为对surface的限制和讨论。然后MLLM找出几个满足constrain function的放置方式,再prompt MLLM去排除那些几何上可行但从审美、功能性或可达性上不合理的放置方案。
- 为了让MLLM在海量视觉选择中做得更直观,文章是按批次进行,并且用上不同色的方法让对比更强一点。
- Metrics概述:自制小dataset,50 scenes和266 placement tasks。由于人类标注也不能当作标准答案(object placement本来就很tricky嘛),所以除了L2之外还加上了energy(constrain函数值小, energy score高) and plausibility scores(类似reward hacking检测)
reading note:
- 这篇paper对我来说有特殊的意义,是在科研混合着保研收到最多负反馈的时候宝总给我推荐的,看到自己想出来的简陋的idea居然可以被这么厉害的组做成solid的工作,很受鼓励(因为水平太烂并没有撞idea的心痛hhh)。“constructing a scene can be seen as an iterative process of object placement”
- 这篇文章的task设置中language prompt的详细程度已经把需要比较和探索的可放置位置大大减少了(我觉得或许科研入门就是弄清楚细微的setting差异会给结果带来巨大的差异这件事)
- 可惜还没开源,next object placement这个新任务本身一定对家居机器人很有意义
推荐指数:🌟🌟🌟🌟
IDesign
- paper link: https://arxiv.org/abs/2404.02838
time: 2024/04
core idea:
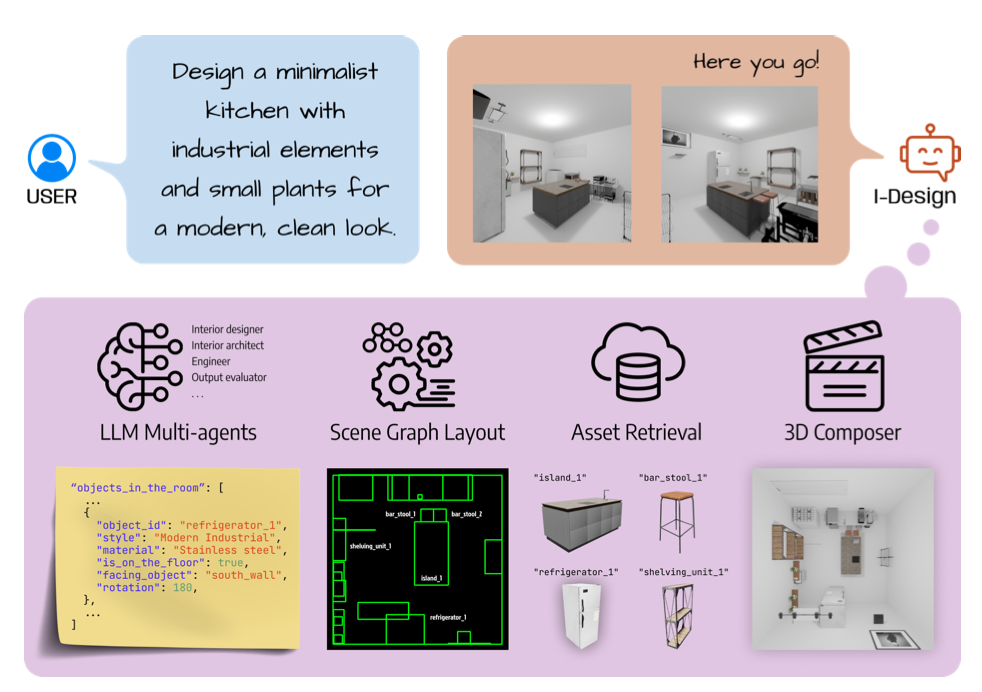
- Multiple LLM agents that take unstructured, grammar-free natural language user input
- Multiple agents powered by AutoGen
- Metrics有Object num, out of boundary, collision, GPT-4V, 一年之后我们还是只有这些然后喜提被喷(😭)
- user study诚意十足,做了将近2000次selecion
reading note:
- 按照时间来算应该是第一批LLM 3DISS的工作了,而且Multiple Agent的设置也颇有前瞻性,值得称道
- 面对自己亲手跑过的baseline有些心情复杂。开源的代码跑起来一点也不丝滑,bbox layout总是碰撞,动不动在某个agent那里两个object有了同一个父对象然后嘎巴停住,很难算出来一个不报错的解。不知道改了多少个try throw才能批量跑出结果来。实际跑出来的东西根本没你们demo那么漂亮啊喂
推荐指数:🌟🌟🌟
Holodeck
- paper link: https://arxiv.org/pdf/2312.09067
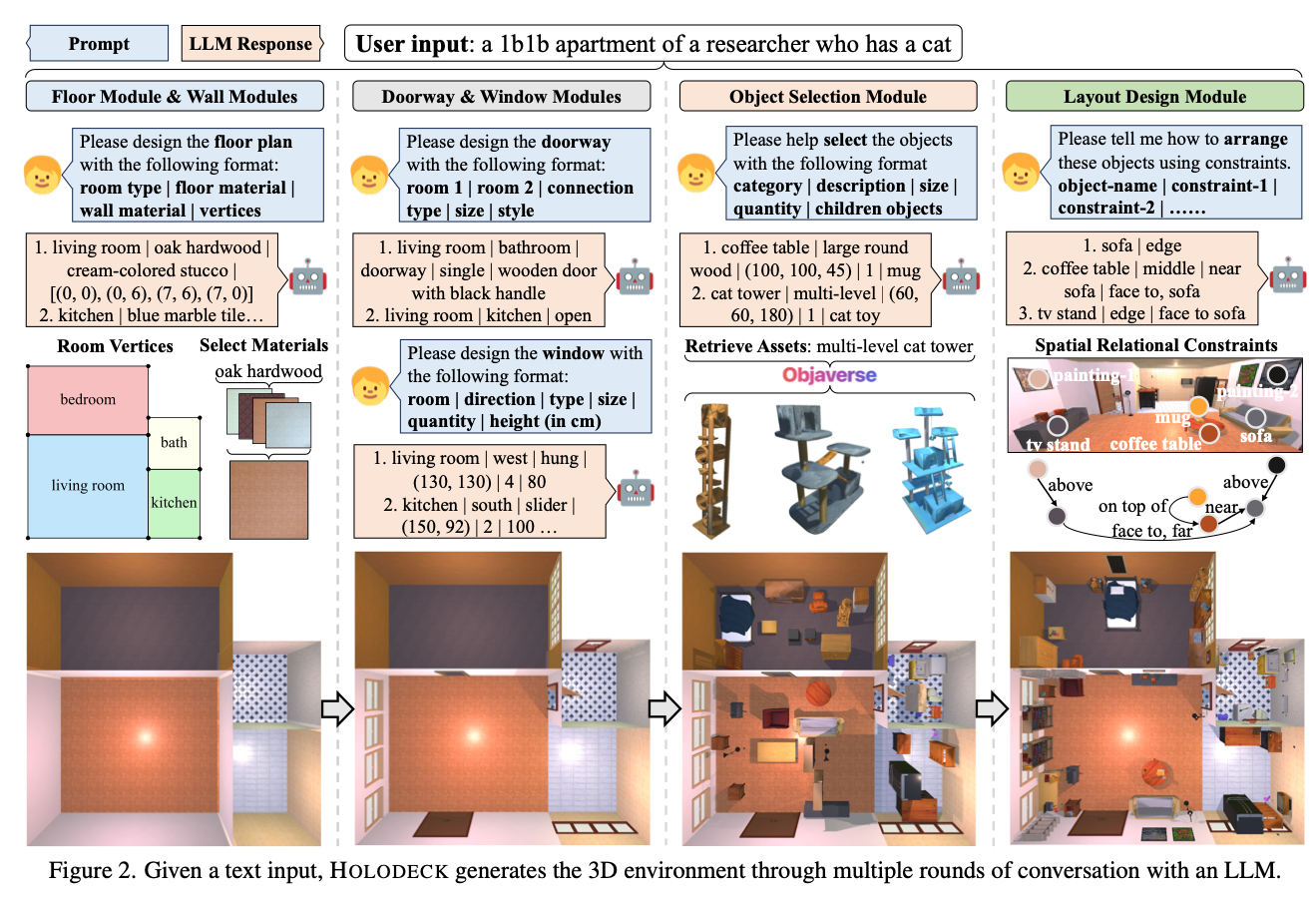
time: 2024/04
core idea:
- 开放生成的同期工作
- dataset用的是objaverse
- 在如何生成具体position(并且保证整个场景互相不冲突)这个难解的问题上选择了物体之间用位置关系graph锚定(above, on top of, face to…),不过有些错误(例如生成房间太小)是直接用prompt解决的诶,流程上也是把设计分成几个module一步一步做了,“人工”智能🤣
reading note:
- 这篇和其他不同的是跟平台绑定的比较紧(AI2Thor),所以配环境、中途截断json文件、导出assets都非常麻烦;另外这是我见过的3DISS paper中唯一一篇考虑户型而且全屋定制的哈哈,比的时候只要了给定房屋大小内的main generation results
- 实际复现的话,如果不调低小物体maximum个数,经常会找不到解跑不出来;如果不写死要生成多少小物体,model容易偷懒啥小物体也不生成…
- user study找的人可真多,680个
- 有下游任务,可以应用到navigation上,开头的EAI并不是说说而已,加分
推荐指数:🌟🌟🌟
LayoutGPT
- paper link:https://arxiv.org/abs/2305.15393
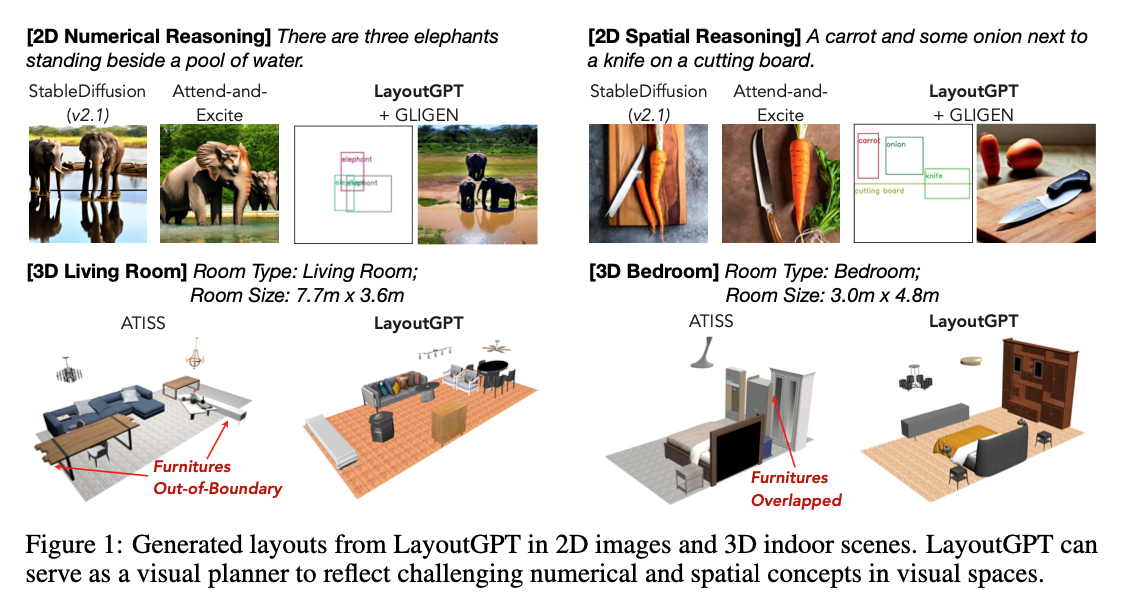
time: 2023/04
core idea: 用GPT通过layout-level进行视觉可控生成,主要在2D image generation的数量的精确控制上,indoor scene感觉涉及的不多
reading note: LLM for layout generation,做得比正统3DISS还要早诶。但是task比较僵化,需要比较详细的prompt才能有好的效果(用跟我们的model一样的简单prompt就生成得巨烂无比),而且依赖3DF的示例,不能跑bedroom/livingroom之外的type因为3DF里根本没有
推荐指数:🌟🌟
Anyhome
- paper link:https://arxiv.org/abs/2312.06644

time: 2023/12
core idea:
- floorplan, layout(都是先有graph关系再用函数放置具体位置的), ego-centric geometric优化(方便走路、倒伏摆正之类的refinement),甚至还有SDS loss的texture优化(更多的文章是直接retrieval现成的资产)
reading note:
- 查了一下作者的高中,深圳国际教育学院,一个国际高中,一作大一没入学就已经62 Google ref,嗯,很震撼。
- 但是从第一次挂出来到现在快两年了还没完全开源,开源的那部分没有小物体放置函数(这是最后求出layout解很关键的一步),想要复现几乎得重写,所以最后就没有跟它比。
- 对这篇文章说的不多,毕竟太久没开源,不知道文中写的formulation代码上怎么实现的
推荐指数:🌟🌟
LayoutVLM
- paper link:https://arxiv.org/abs/2412.02193
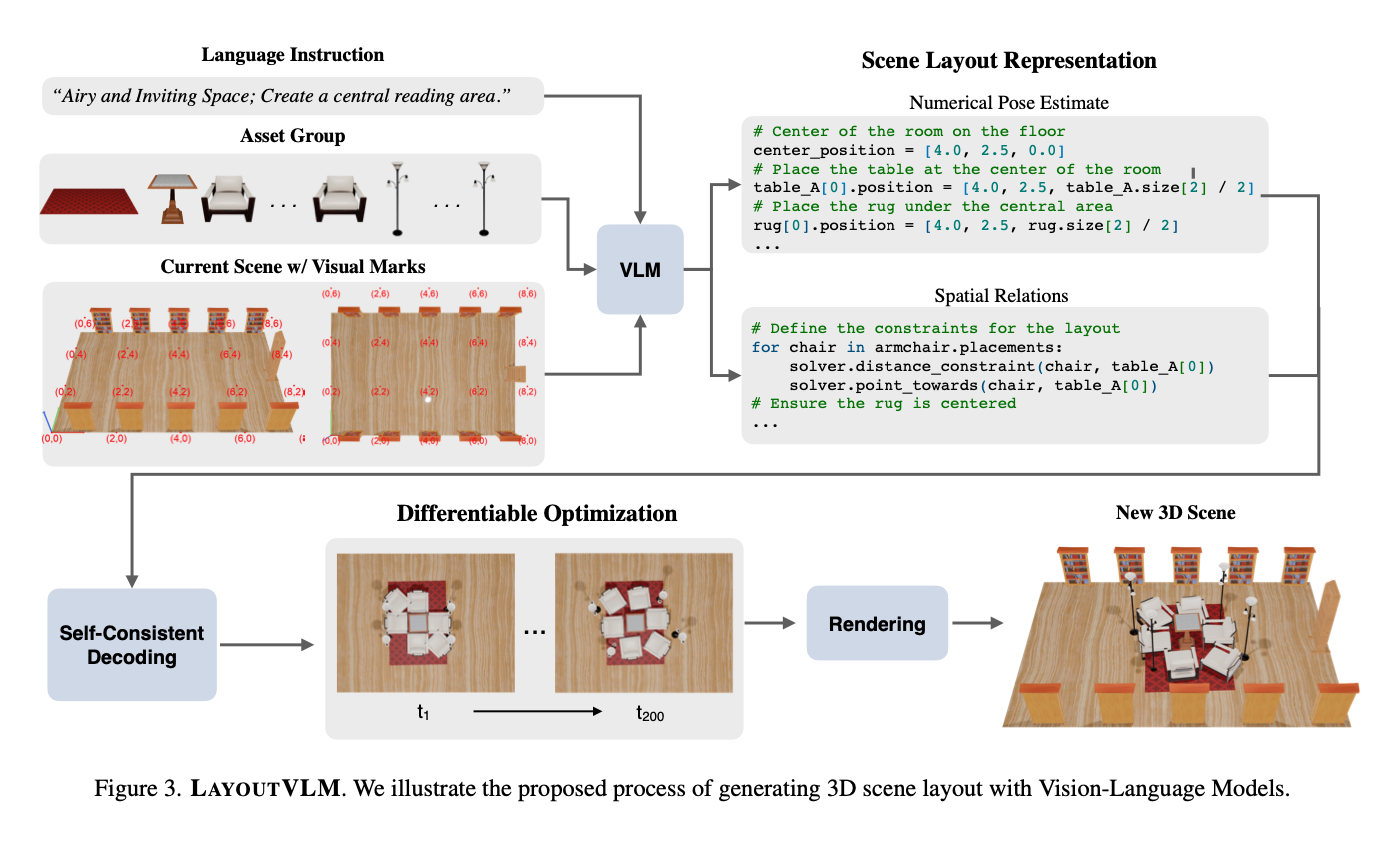
time: 2024/12
core idea:
- Foundation models still struggle with 3D reasoning tasks like arranging objects in space according to open-ended language instructions, particularly in dense and physically constrained environments.
- 五种位置关系$$L_{distance}(p_i, p_j, d_{min}, d_{max}),L_{\text{on_top_of}}(p_i, p_j, b_i, b_j),L_{\text{align_with}}(p_i, p_j, \phi)$$ $$L_{\text{point_towards}}(p_i, p_j, \phi),L_{\text{against_wall}}(p_i, w_j, b_i)$$
- 两种表示(位置关系vs具体位姿)互相优化
- 通过优化对「空间关系」+「位姿优化」的生成能力,能显著提高各大VLM的initial layout预测质量
reading note:
text prompt的细致程度大概中等,远没有diffuscene那么模拟。第一步是用辅助spatial reasoning的visual cue(coordiante points)帮助LLM生成initial scene和空间关系,专门有一步生成initial layout是必要的,因为后续的differentiable改动较小,需要一个好的奠基。生成过程有特别注意一个group接着一个group进行,每次生成完再给一个visual cue(image rendering)
空间关系筛选:位置关系->具体坐标layout求解困难(这个步骤说高级点应该叫layout decoding)确实是最困难的步骤之一。文章要求VLM预测的两种不同的表示形式并彼此自洽,具体操作来说,是以初始状态生成的位姿为主,排除后续与初始位姿误差达到一定程度的位置关系,不予优化。$$L_{\text{semantic}} = \sum_{L_i \in \mathcal{R}} \mathbf{1}\left[L_i(\hat{p}_i, \hat{p}_j, \lambda) \leq \epsilon\right] \cdot L_i(p_i, p_j, \lambda)$$
位姿优化:把$L_{semantic}$和$L_{physics}$的和作为loss,然后用PGD优化object位姿。$$L_{physics} = \sum_{i=1}^{N} \sum_{j=1}^{N} L_{DIoU}(p_i, p_j, b_i, b_j)$$
如上所述,初始的位姿和空间关系是生成的重中之重,所以文章把已有dataset的物体姿态 + 空间关系作为label来finetune VLM,让VLM直接学会准确地根据当前3D场景的渲染图 + asset可视图 + 文字说明去预测label。
evaluation中作者用了自己的dataset, 有GT,看来标准还是教VLM学会生成空间布局(我的理解,这个任务setting就好像ACM里面说的大模拟)
user study虽然人少,但是分析做得很足(自从被四个审稿人都骂了一遍之后每次看paper必看user study)
是idea非常扎实的好paper!
推荐程度:🌟🌟🌟🌟