Reinforcement Learning
写在前面
Sim RL, real world RL, RL with Human-in-the-loop, 我们寻找reward,为科研也为生活。
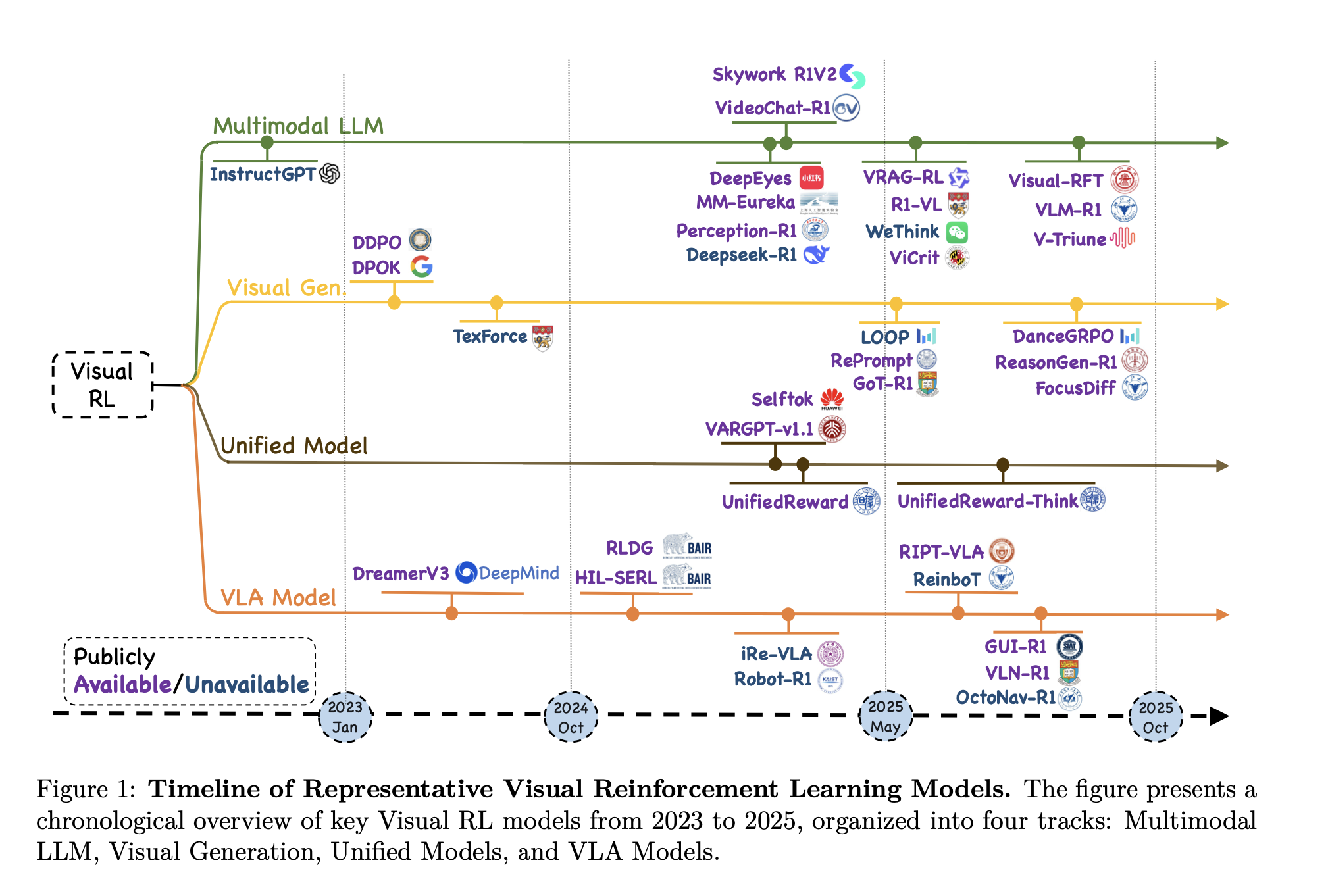
RL & VLA: A Review
What Can RL Bring to VLA Generalization? An Empirical Study
- paper link: https://arxiv.org/abs/2505.19789
- time: 25/06
- core idea:
- reading note:
- 推荐指数:
MoRE(No-env offline)
Unlocking Scalability in Reinforcement Learning for Quadruped Vision-Language-Action Models
- paper link: https://arxiv.org/abs/2503.08007
- time: 25/06
- core idea:
- reading note:
- 推荐指数:
ReinboT(No-env offline)
Amplifying Robot Visual-Language Manipulation with Reinforcement Learning
- paper link: https://arxiv.org/abs/2503.08007
- time: 25/03
- core idea:
- reading note:
- 推荐指数:
OctoNav(Env-sim online)
Towards Generalist Embodied Navigation
- paper link: https://arxiv.org/pdf/2506.09839
- time: 25/06
- core idea:
- reading note:
- 推荐指数:
ConRFT(Env-real online, RSS)
A Reinforced Fine-tuning Method for VLA Models via Consistency Policy
- paper link: https://arxiv.org/abs/2502.05450
- time: 25/02
- core idea:
- reading note:
- 推荐指数:
RLGD(Env-real online, RSS)
- paper link: https://arxiv.org/abs/2412.09858
- time: 25/06
- core idea:
- reading note:
- 推荐指数:
Policy Agnostic(Env-real online)
Offline RL and Online RL Fine-Tuning of Any Class and Backbone
- paper link: https://arxiv.org/abs/2412.09858
- time: 25/06
- core idea:
- reading note:
- 推荐指数:
GRAPE (test time)
Generalizing Robot Policy via Preference Alignment
- paper link: https://arxiv.org/pdf/2411.19309
- time: 24/11
- core idea:
- reading note:
- 推荐指数:
BAIR (science, real) Precise and Dexterous Robotic Manipulation via Human-in-the-Loop Reinforcement Learning
paper link: https://arxiv.org/abs/2410.21845
time: 2024/10
core idea:
reading note: omg读会读多了,期刊真的不太好读啊…正文22页我哭死
推荐指数: